

通過百億(yi) 參數級基礎模型與(yu) 強化學習(xi) 驅動的世界模型,打造多模態智能駕駛大模型(Motovis大模型)。該技術兼具泛化能力與(yu) 場景適應能力,支持跨模態數據交互與(yu) 智能決(jue) 策,可靈活部署於(yu) 嵌入式平台,構建高度擬人化的駕駛智能體(ti) ,提升智能駕駛係統的安全性與(yu) 智能化水平。
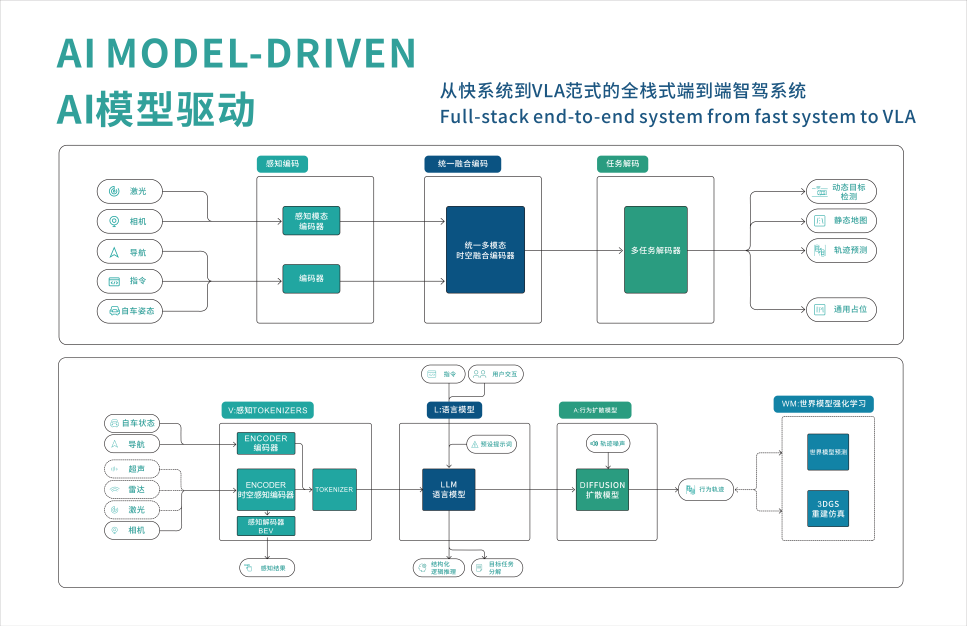
MOTOVIS VLA基礎大模型框架,是認知模型的基礎,是以視覺編碼器,視覺語言模型,動作策略模型為(wei) 基礎,以世界模型為(wei) 強化學習(xi) 環境,以4D數據集,VQA數據集,法規數據集,物理交互數據集作Fine Tune。






